泷泽萝拉第二部 千万级大表分页查询着力剧降, 你会何如办?
发布日期:2025-01-01 08:23 点击次数:186

一、问题复现泷泽萝拉第二部
在实质的软件系统建立经由中,跟着使用的用户群体越来越多,表数据也会跟着时刻的推移,单表的数据量会越来越大。
以订单表为例,假如每天的订单量在 4 万足下,那么一个月的订单量即是 120 多万,一年即是 1400 多万,跟着年数的加多和单日下单量的加多,订单表的数据量会越来越庞杂,订单数据的查询不会像率先那样浅薄快速,要是查询要道字段莫得走索引,会径直影响到用户体验,以致会影响到就业是否能平淡运转!
底下我以某个电商系统的客户表为例,数据库是 MySQL,数据体量在 100 万以上,精通先容分页查询下,不同阶段的查询着力情况(订单表的情况亦然相通的,只不外它的数据体量比客户表更大)。
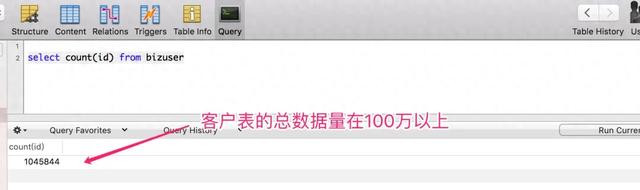
底下咱们扫数来测试一下,每次查询客户表时最多复返 100 条数据,不同的肇始下,数据库查询性能的各异。
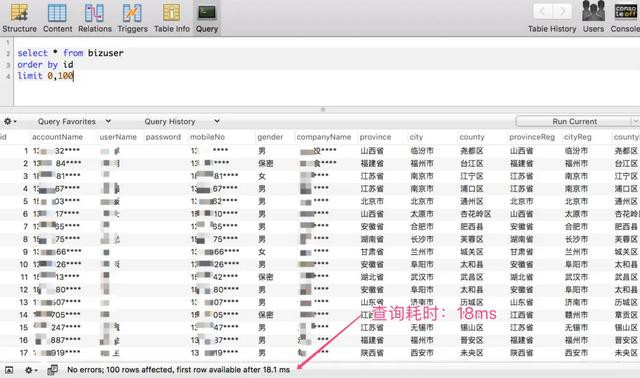
当开头位置在 0 的时候,仅耗时:18 ms
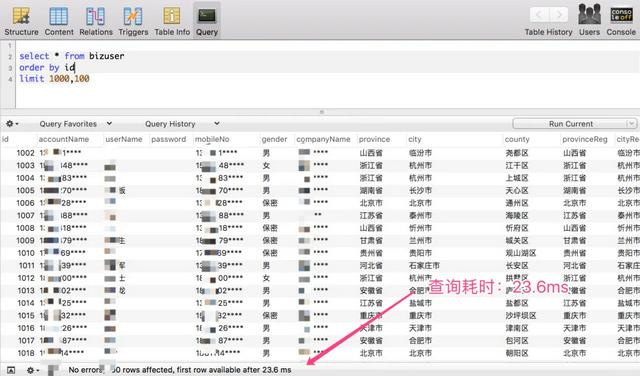
当开头位置在 1000 的时候,仅耗时:23 ms
当开头位置在 10000 的时候,仅耗时:54 ms
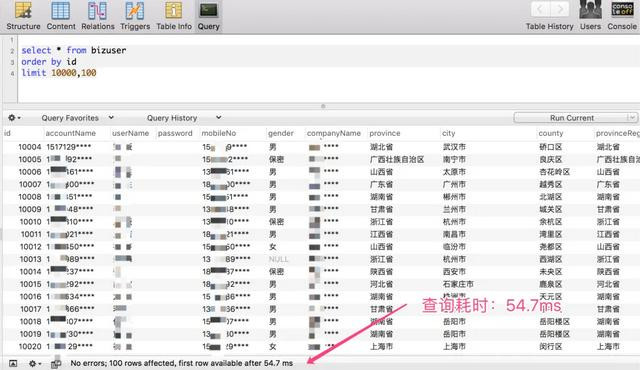
当开头位置在 100000 的时候,仅耗时:268 ms
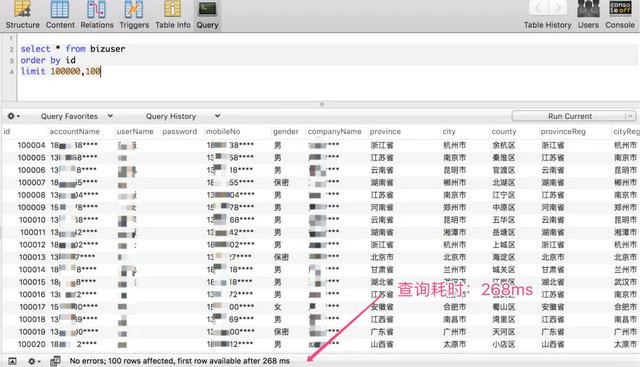
当开头位置在 500000 的时候,仅耗时:1.16 s
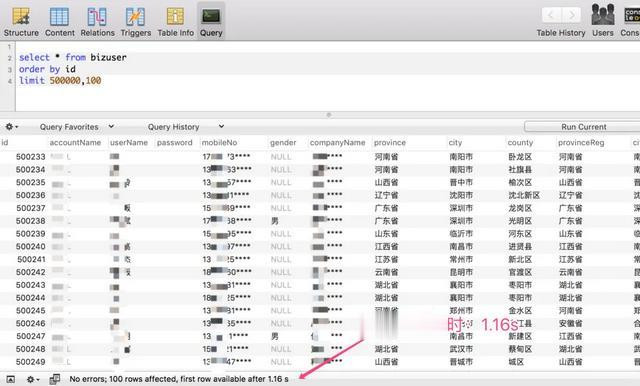
当开头位置在 1000000 的时候,仅耗时:2.35 s
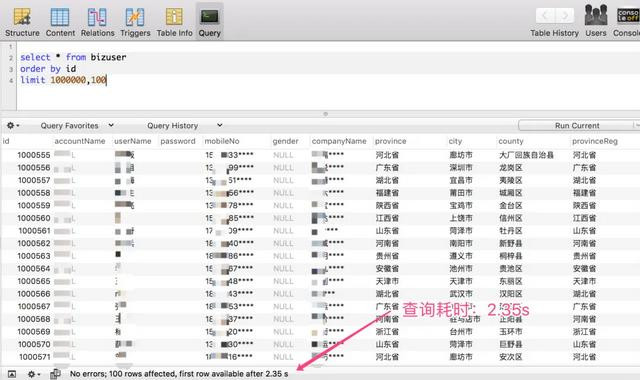
不错非常知晓的看出,跟着开头位置越大,分页查询着力成倍的下落,当开头位置在 1000000 以上的时候,对于百万级数据体量的单表,查询耗时基本上以秒为单元。
而事实上,一般查询耗时逾越 1 秒的 SQL 齐被称为慢 SQL,有的公司运维组要求的可能愈加严格,比如小编我所在的公司,要是 SQL 的践诺耗时逾越 0.2s,也被称为慢 SQL,必须在限定的时刻内尽快优化,否则可能会影响就业的平淡运转和用户体验。
对于千万级的单表数据查询,小编我刚刚也使用了一下分页查询,开头位置在 10000000,也截图给全球望望,查询耗时收尾:39 秒!
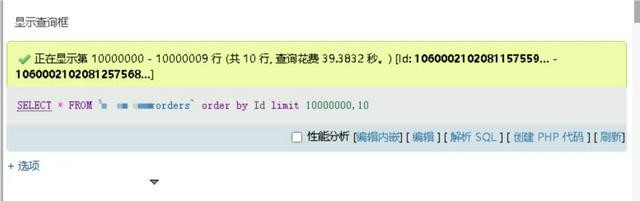
莫得斗殴过这样大数据体量的同学,可能几许对这种查询收尾会感到吃惊,事实上,这还仅仅数据库层面的耗时,还莫得算后端就业的处理链路时刻,以及复返给前端的数据渲染时刻,以百万级的单表查询为例,要是数据库查询耗时 1 秒,再经事后端的数据封装处理,前端的数据渲染处理,以及收罗传输时刻,莫得特别的情况下,差未几在 3~4 秒之间,可能有些同学对这个肯求时长数值还不太敏锐。
据互联网软件用户体验报告,当平均肯求耗时在1秒之内,用户体验是最好的,此时的软件亦然用户留存度最高的;2 秒之内,还对付过的去,用户能继承;当逾越 3 秒,体验会稍差;逾越 5 秒,基本上会卸载刻下软件。
有的公司为了进步用户体验,会严格适度肯求时长,当肯求时长逾越 3 秒,自动拔除肯求,从而倒逼本领优化疗养 SQL 语句查询逻辑,以致疗养后端举座架构,比如引入缓存中间件 redis,搜索引擎 elasticSearch 等等。
继续回到咱们本文所需要研讨的问题,当单表数据量到达百万级的时候,查询着力急剧下落,怎样优化进步呢?
二、处罚决议
底下咱们扫数来望望具体的处罚主张。
决议一:查询的时候,只复返主键 ID
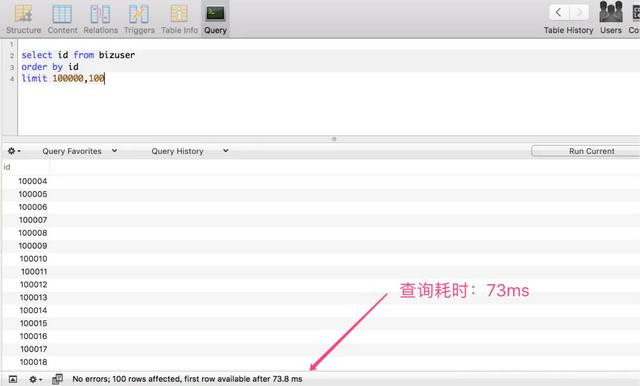
咱们继续回到上文给全球先容的客户表查询,将select *改成select id,简化复返的字段,咱们再来不雅察一下查询耗时。
当开头位置在 100000 的时候,仅耗时:73 ms
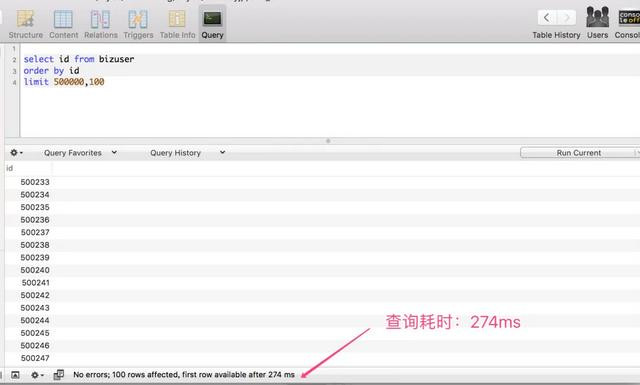
当开头位置在 500000 的时候,仅耗时:274 ms
当开头位置在 1000000 的时候,仅耗时:471 ms
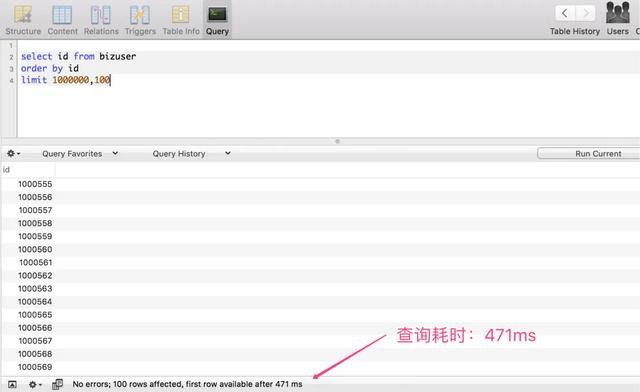
不错很知晓的看到,通过简化复返的字段,不错很权贵的成倍进步查询着力。
实质的操作想路即是先通过分页查询骄横条款的主键 ID,然后通过主键 ID 查询部分数据,不错权贵进步查询后果。
-- 先分页查询骄横条款的主键IDselect id from bizuser order by id limit 100000,10;-- 再通过分页查询复返的ID,批量查询数据select * from bizuser where id in (1,2,3,4,.....);
决议二:查询的时候,通过主键 ID 过滤
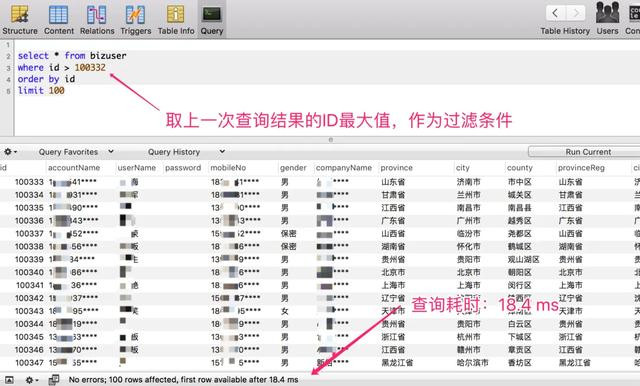
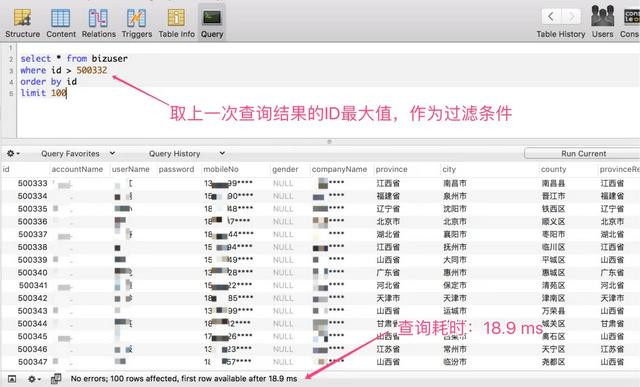
这种决议有一个要求即是主键ID,必须是数字类型,践诺的想路即是取上一次查询收尾的 ID 最大值,动作过滤条款,何况排序字段必须是主键 ID,否则分页排序法规会庞杂。
查询 100000~1000100 区间段的数据,仅耗时:18 ms
查询 500000~5000100 区间段的数据,仅耗时:18 ms
查询 1000000~1000100 区间段的数据,仅耗时:18ms
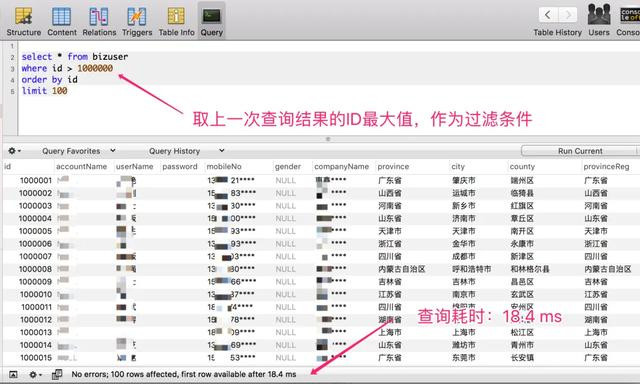
不错很知晓的看到,带上主键 ID 动作过滤条款,查询性能非常的踏实,基本上在20 ms内不错复返。
这种决议还短长常可行的,要是刻下业务对排序要求未几,不错选拔这种决议,性能也非常杠!
然则要是刻下业务对排序有要求,比如通过客户终末修改时刻、客户终末下单时刻、客户终末下单金额等字段来排序,那么上头先容的【决议一】,比【决议二】查询着力更高!
决议三:选拔 elasticSearch 动作搜索引擎
当数据量越来越大的时候,尤其是出现分库分表的数据库,以上通过主键 ID 进行过滤查询,后果可能会不尽东谈主意,举例订单数据的查询,这个时候比拟好的处罚主张即是将订单数据存储到 ElasticSearch 中,通过 elasticSearch 结束快速分页和搜索,后果进步也短长常显然。
对于 ElasticSearch 的玩法,之前有给全球先容过具体的践诺,这里不在过多撰书。
干妹妹三、小结
不知谈全球有莫得发现,上文中先容的表主键 ID 齐是数值类型的,之是以选拔数字类型动作主键,是因为数字类型的字段能很好的进行排序。
但要是刻下表的主键 ID 是字符串类型,比如 uuid 这种,就没主张结束这种排序特质,何况搜索性能也非常差,因此不冷落全球选拔 uuid 动作主键ID,具体的数值类型主键 ID 的生成决议有许多种,比如自增、雪花算法等等,齐能很好的骄横咱们的需求。
本文主要围绕大表分页查询性能问题,以及对应的处罚决议作念了浅薄的先容,要是有异议的场所,迎接网友留言,扫数计算学习!
作家丨志哥聊本领泷泽萝拉第二部